Pengenalan dan Implementasi Algoritma K-Means Clustering dengan Python
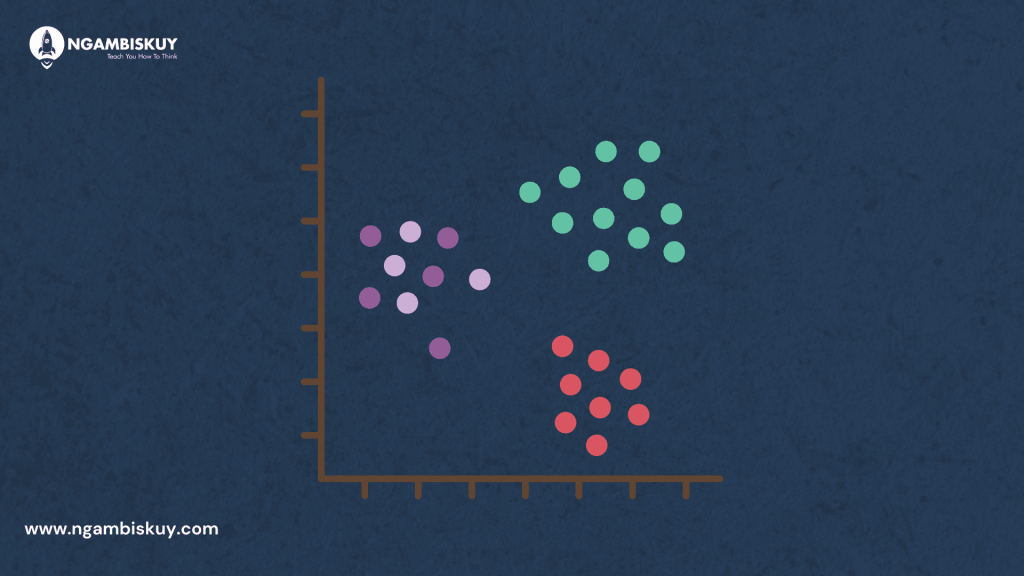
Clustering adalah salah satu teknik penting dalam analisis data dan machine learning yang digunakan untuk mengidentifikasi struktur dalam data. Proses ini mengelompokkan data ke dalam beberapa kelompok atau “cluster” berdasarkan kesamaan antara data. Tujuannya adalah untuk membuat data di dalam satu cluster sejenis dan berbeda dari data di cluster lainnya. Clustering memiliki berbagai aplikasi praktis termasuk segmentasi pelanggan, analisis outlier, dan pengurangan dimensi.
Algoritma K-Means adalah salah satu algoritma clustering yang paling populer dan mudah dipahami. Algoritma ini bekerja dengan mengidentifikasi K pusat cluster (di mana K adalah jumlah cluster yang diinginkan) dan mengalokasikan setiap titik data ke cluster terdekat berdasarkan jarak euclidean. Proses ini diulangi hingga pusat cluster tidak berubah lagi, menunjukkan bahwa algoritma telah menemukan pusat cluster optimal. K-Means adalah algoritma berbasis jarak yang efisien dan dapat diterapkan pada dataset besar.
Menurut tinjauan komprehensif, algoritma K-Means telah mengalami berbagai variasi dan kemajuan, terutama di era big data. Analisis ini menyoroti bagaimana K-Means telah beradaptasi dengan tuntutan analisis data skala besar dan menampilkan berbagai varian algoritma yang telah dikembangkan untuk menangani kelemahan khusus dari pendekatan K-Means tradisional. Dengan kemajuan ini, K-Means tetap relevan dan menjadi alat yang sangat berguna dalam toolkit analisis data setiap profesional data dan pengembang.
Dasar-dasar Algoritma K-Means
Algoritma K-Means adalah pendekatan yang sistematis untuk clustering data berdasarkan kesamaan atau perbedaan antara data point. Berikut adalah langkah-langkah dasar dari algoritma K-Means:
1. Bagaimana Algoritma K-Means Bekerja:
- Algoritma ini dimulai dengan menentukan jumlah cluster, K, yang ingin diidentifikasi dari data.
- Setelah itu, K pusat cluster awal dipilih secara acak dari data.
- Kemudian, setiap data point dikelompokkan ke dalam cluster terdekat berdasarkan jarak euclidean ke pusat cluster.
- Pusat cluster kemudian diperbarui dengan menghitung rata-rata dari semua data point dalam cluster tersebut.
- Proses ini diulangi hingga pusat cluster tidak berubah lagi atau berubah sangat sedikit, menunjukkan konvergensi algoritma.
2. Inisialisasi Centroid:
- Inisialisasi centroid merupakan langkah krusial dalam algoritma K-Means karena hasil clustering sangat bergantung pada pemilihan centroid awal.
- Beberapa metode umum untuk inisialisasi centroid termasuk pemilihan acak, pemilihan berdasarkan analisis sebelumnya, atau metode k-means++ yang mencoba meminimalkan bias dalam pemilihan centroid.
3. Alokasi Cluster dan Pembaruan Centroid:
- Setelah centroid diinisialisasi, setiap data point diatribusikan ke cluster terdekat berdasarkan jarak ke centroid.
- Setelah semua data point diatribusikan ke cluster, centroid diperbarui dengan menghitung rata-rata dari semua data point dalam cluster tersebut.
- Proses alokasi dan pembaruan ini diulangi hingga tidak ada perubahan lebih lanjut dalam pusat cluster atau perubahan tersebut di bawah ambang batas yang telah ditentukan.
Algoritma K-Means adalah metode yang efisien dan efektif untuk clustering data, namun, pemilihan centroid awal dan jumlah cluster yang tepat sangat penting untuk mendapatkan hasil clustering yang optimal. Buku “K-Means Clustering” memberikan pandangan mendalam tentang bagaimana algoritma K-Means bekerja dan bagaimana melakukan inisialisasi centroid yang tepat serta proses iteratif alokasi cluster dan pembaruan centroid untuk mencapai hasil clustering yang diinginkan.
Persiapan Data untuk K-Means
Sebelum melaksanakan algoritma K-Means, penting untuk mempersiapkan data dengan baik untuk memastikan hasil clustering yang akurat dan bermakna. Berikut adalah langkah-langkah penting dalam persiapan data:
1. Import Data:
- Langkah pertama dalam persiapan data adalah mengimpor data ke dalam lingkungan pemrograman seperti Python. Ini dapat dilakukan menggunakan library seperti Pandas yang menyediakan fungsionalitas untuk membaca berbagai format data seperti CSV, Excel, dan SQL.
2. Eksplorasi dan Pembersihan Data:
- Setelah data diimpor, langkah selanjutnya adalah melakukan eksplorasi untuk memahami karakteristik dan struktur data. Ini termasuk identifikasi variabel penting, mengecek nilai yang hilang, dan mendeteksi outlier.
- Pembersihan data adalah proses mengatasi masalah-masalah dalam data seperti nilai yang hilang, outlier, dan kesalahan entri. Ini dapat mencakup pengisian nilai yang hilang, penghapusan outlier, atau koreksi kesalahan.
3. Normalisasi Data:
- Karena algoritma K-Means berbasis jarak, sangat penting untuk menormalkan data sehingga setiap fitur memiliki skala yang serupa. Ini akan memastikan bahwa setiap fitur memiliki pengaruh yang sama terhadap hasil clustering.
- Metode normalisasi populer termasuk Min-Max Scaling dan Standardization (Z-score Scaling). Min-Max Scaling mengubah skala data sehingga berada dalam rentang tertentu, seperti 0 hingga 1, sementara Standardization menyesuaikan data untuk memiliki rata-rata 0 dan deviasi standar 1.
Persiapan data adalah langkah krusial dalam proses clustering dengan K-Means. Data yang baik dan terstruktur dengan baik akan memungkinkan algoritma bekerja dengan lebih efektif dan menghasilkan insight yang lebih bermakna dari proses clustering. Seiring dengan langkah-langkah di atas, mungkin juga perlu untuk melakukan reduksi dimensi atau pemilihan fitur untuk memastikan bahwa data yang paling relevan dan informatif digunakan dalam proses clustering.
Implementasi K-Means dengan Python
Python adalah bahasa pemrograman yang sangat populer untuk analisis data dan machine learning. Library Scikit-Learn pada Python menyediakan implementasi efisien dari algoritma K-Means yang memudahkan penggunaan algoritma ini untuk clustering data. Berikut adalah langkah-langkah untuk implementasi K-Means dengan Python:
1. Menggunakan Library Scikit-Learn:
- Untuk memulai, Anda perlu mengimpor library Scikit-Learn dan library lain yang mungkin diperlukan seperti Pandas dan Matplotlib untuk manipulasi data dan visualisasi.
- Scikit-Learn menyediakan kelas KMeans yang membuat implementasi algoritma K-Means menjadi sederhana dan langsung.
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
2. Langkah-langkah Implementasi K-Means:
- Pengumpulan Data: Mulailah dengan mengumpulkan dan mempersiapkan data Anda. Ini mungkin termasuk import data, eksplorasi, pembersihan, dan normalisasi seperti yang dibahas dalam bagian sebelumnya.
- Menginstansiasi Model K-Means: Buat instance dari kelas KMeans, tentukan jumlah cluster yang diinginkan dan parameter lainnya sesuai kebutuhan.
kmeans = KMeans(n_clusters=3) - Fit Model ke Data: Gunakan metode fit untuk melatih model K-Means pada data Anda.
kmeans.fit(data) - Mendapatkan Hasil Clustering: Setelah model dilatih, Anda dapat menggunakan atribut labels_ untuk mendapatkan label cluster untuk setiap data point dan cluster_centers_ untuk mendapatkan pusat cluster.
labels = kmeans.labels_
centers = kmeans.cluster_centers_
3. Interpretasi Hasil Clustering:
- Interpretasi hasil clustering adalah langkah penting untuk memahami apa yang diungkapkan clustering tentang data Anda.
- Visualisasi hasil clustering bisa sangat membantu. Gunakan library visualisasi seperti Matplotlib atau Seaborn untuk menampilkan data point dan pusat cluster dalam ruang fitur.
- Selain itu, analisis statistik dan eksplorasi lebih lanjut dari cluster dapat memberikan insight lebih lanjut tentang kelompok-kelompok data dan apa yang membedakan satu cluster dari yang lain.
Melalui implementasi K-Means dengan Python, Anda dapat dengan mudah menerapkan algoritma clustering ini untuk menganalisis dan memahami struktur dalam data Anda. Dengan memahami dan menginterpretasikan hasil clustering, Anda dapat mengidentifikasi pola dan insight berharga yang dapat membantu dalam pengambilan keputusan atau analisis lebih lanjut.
Evaluasi dan Optimasi Model K-Means
Setelah implementasi algoritma K-Means, penting untuk mengevaluasi dan mengoptimalkan model untuk mendapatkan hasil clustering yang lebih akurat dan bermakna. Berikut adalah langkah-langkah dalam evaluasi dan optimasi model K-Means:
1. Metrik Evaluasi: Inertia dan Silhouette Score:
- Inertia: Merupakan jumlah kuadrat jarak dari setiap data point ke pusat cluster terdekatnya. Nilai inertia yang lebih rendah menunjukkan bahwa data point lebih dekat ke pusat cluster, namun nilai terlalu rendah bisa menunjukkan overfitting. Di Scikit-Learn, nilai inertia dapat diakses melalui atribut inertia_ dari objek KMeans.
inertia = kmeans.inertia_ - Silhouette Score: Merupakan rasio antara jarak antar-cluster dan jarak intra-cluster. Skor silhouette berkisar antara -1 hingga 1. Nilai yang lebih tinggi menunjukkan bahwa objek cocok dengan baik dengan cluster mereka sendiri dan buruk dengan cluster tetangga. Skor silhouette dapat dihitung dengan fungsi silhouette_score di Scikit-Learn.
from sklearn.metrics import silhouette_score
score = silhouette_score(data, kmeans.labels_)
2. Menentukan Jumlah Cluster Optimal dengan Metode Elbow:
- Metode elbow adalah teknik umum untuk menentukan jumlah cluster optimal (K). Ini melibatkan pencocokan model K-Means ke data dengan berbagai nilai K dan ploting inertia terhadap K. Titik “siku” di plot, di mana penurunan inertia mulai melambat, menunjukkan jumlah cluster optimal.
inertia = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i)
kmeans.fit(data)
inertia.append(kmeans.inertia_)
plt.plot(range(1, 11), inertia)
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('Inertia')
plt.show()
- Secara visual, titik ‘elbow’ akan menunjukkan di mana peningkatan jumlah cluster tidak lagi menyebabkan penurunan inertia yang signifikan, dan ini bisa dianggap sebagai indikasi jumlah cluster yang baik.
Evaluasi dan optimasi model sangat penting untuk memastikan bahwa model K-Means Anda bekerja seefektif mungkin dan menghasilkan insight yang berguna dan bermakna. Metrik evaluasi dan metode elbow memberikan alat yang kuat untuk mengukur kinerja dan meningkatkan hasil clustering Anda.
Visualisasi Hasil Clustering
Visualisasi adalah alat yang sangat kuat untuk menginterpretasikan hasil dari algoritma clustering. Ini membantu dalam memahami bagaimana data dikelompokkan dan bagaimana cluster berbeda satu sama lain. Berikut adalah langkah-langkah untuk melakukan visualisasi dan interpretasi dari hasil clustering:
1. Visualisasi Cluster dengan Matplotlib dan Seaborn:
- Matplotlib dan Seaborn adalah library visualisasi data yang populer di Python yang memungkinkan Anda untuk membuat plot beragam dan informatif dengan mudah.
- Untuk visualisasi hasil clustering, Anda dapat menggunakan scatter plot untuk menampilkan data point dalam ruang fitur dan menyoroti cluster berbeda dengan warna atau marker yang berbeda.
import matplotlib.pyplot as plt
import seaborn as sns
# Tentukan warna untuk setiap cluster
palette = sns.color_palette('deep', kmeans.n_clusters)
# Buat scatter plot sns.scatterplot(data=data, x='Fitur1', y='Fitur2', hue=kmeans.labels_, palette=palette)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red') # Tandai pusat cluster
plt.title('Visualisasi Cluster K-Means')
plt.show()
2. Interpretasi Visual dari Cluster:
- Interpretasi visual memungkinkan Anda untuk melihat bagaimana data dikelompokkan dan untuk mengidentifikasi pola atau tren dalam data.
- Dari plot, Anda dapat melihat bagaimana data point dikelompokkan bersama dan bagaimana pusat cluster membagi ruang fitur. Anda juga dapat melihat apakah ada overlap antar cluster atau jika ada area di mana data point jarang terjadi.
- Selain itu, analisis lebih lanjut dari karakteristik setiap cluster dapat membantu dalam memahami apa yang membuat satu cluster berbeda dari yang lain dan bagaimana karakteristik ini sesuai dengan masalah atau tujuan analisis Anda.
Visualisasi dan interpretasi visual adalah langkah penting dalam analisis hasil clustering. Dengan melihat bagaimana data dikelompokkan dalam ruang fitur dan memahami perbedaan antar cluster, Anda dapat memperoleh insight berharga yang dapat membantu dalam analisis lebih lanjut atau pengambilan keputusan berbasis data.
Aplikasi Praktis dari K-Means
Algoritma K-Means memiliki berbagai aplikasi praktis di banyak bidang dan industri. Berikut adalah beberapa aplikasi umum dan contoh kasus bisnis untuk algoritma K-Means:
1. Contoh Kasus Bisnis:
- Segmentasi Pelanggan: Bisnis sering menggunakan K-Means untuk mengidentifikasi segmen pelanggan berdasarkan karakteristik seperti usia, pendapatan, perilaku pembelian, dan preferensi. Ini membantu bisnis dalam merancang strategi pemasaran dan penjualan yang lebih efektif.
- Optimasi Inventori: K-Means dapat digunakan untuk mengidentifikasi pola dalam data penjualan untuk membantu dalam perencanaan inventori dan manajemen rantai pasokan.
- Deteksi Penipuan: Dalam sektor keuangan, K-Means dapat digunakan untuk mengidentifikasi aktivitas mencurigakan atau outlier yang mungkin menunjukkan penipuan.
2. K-Means dalam Analisis Pelanggan dan Segmentasi Pasar:
- Segmentasi pasar adalah teknik pemasaran kunci yang memungkinkan bisnis untuk memahami dan menargetkan pelanggan dengan lebih baik. K-Means adalah alat yang efektif untuk segmentasi pasar berdasarkan data pelanggan.
- Misalnya, K-Means dapat digunakan untuk mengidentifikasi grup pelanggan yang memiliki kebiasaan pembelian serupa atau preferensi produk yang serupa. Ini dapat membantu bisnis dalam mengembangkan produk atau penawaran promosi yang lebih menarik bagi segmen pasar tertentu.
- Selain itu, analisis lebih lanjut dari cluster pelanggan dapat membantu dalam mengidentifikasi peluang untuk peningkatan layanan atau pengembangan produk baru.
Aplikasi praktis dari K-Means dalam bisnis menunjukkan bagaimana algoritma ini dapat membantu organisasi dalam membuat keputusan berbasis data untuk meningkatkan kinerja dan mencapai tujuan bisnis. Dari segmentasi pelanggan hingga deteksi penipuan, K-Means menyediakan cara yang kuat untuk mengekstrak insight berharga dari data.
Challenges dan Solusi dalam Implementasi K-Means
Implementasi algoritma K-Means bisa menemui sejumlah tantangan yang mempengaruhi efektivitas dan kinerja algoritma. Berikut adalah beberapa tantangan utama dan solusi yang mungkin:
1. Masalah Inisialisasi Centroid:
- Tantangan: Pemilihan centroid awal yang tidak tepat dapat mengarah ke hasil clustering yang sub-optimal atau bahkan salah. Ini karena algoritma K-Means sensitif terhadap inisialisasi centroid.
- Solusi:
- Metode K-Means++: Metode ini memilih centroid awal dengan cara yang lebih cerdas untuk mengurangi probabilitas solusi sub-optimal. Centroid pertama dipilih secara acak, sementara centroid berikutnya dipilih dari data yang belum dipilih dengan probabilitas yang proporsional terhadap kuadrat jaraknya ke titik terdekat yang sudah dipilih sebagai centroid.
- Pengulangan Multiple: Jalankan algoritma K-Means beberapa kali dengan inisialisasi centroid acak berbeda dan pilih hasil dengan inertia terendah.
2. Scalabilitas dan Optimasi Performa:
- Tantangan: K-Means bisa sangat memakan waktu dan sumber daya komputasi, terutama untuk dataset besar dengan banyak fitur atau dimensi tinggi.
- Solusi:
- Reduced Dimensionality: Gunakan teknik reduksi dimensi seperti Principal Component Analysis (PCA) untuk mengurangi jumlah dimensi data sebelum menjalankan algoritma K-Means. Ini akan mengurangi kompleksitas komputasi dan waktu eksekusi.
- Mini Batch K-Means: Versi ini dari algoritma K-Means menggunakan subset data yang lebih kecil atau “mini-batch” untuk mengupdate centroid pada setiap iterasi, mengurangi waktu komputasi secara signifikan tanpa kompromi yang besar pada kualitas hasil clustering.
- Optimasi Hardware dan Software: Gunakan hardware yang lebih cepat dan optimasi software seperti vektorisasi dan paralelisasi untuk meningkatkan performa K-Means.
Menangani tantangan-tantangan ini dengan solusi yang tepat akan memungkinkan implementasi K-Means yang lebih efisien dan efektif, memungkinkan Anda untuk memperoleh insight yang lebih baik dan lebih cepat dari data Anda.
Rangkuman Pengalaman Belajar Algoritma K-Means:
- Belajar dan menerapkan algoritma K-Means adalah pengalaman yang mengedukasi dan memungkinkan pengumpulan insight penting dari data. Dengan memahami dasar-dasar algoritma, melakukan persiapan data yang tepat, implementasi, evaluasi, dan visualisasi, Anda dapat menghasilkan pemahaman yang lebih baik tentang struktur data dan identifikasi kelompok-kelompok yang bermakna dalam data tersebut.
- Tantangan seperti inisialisasi centroid yang tidak tepat dan masalah skalabilitas mungkin muncul, namun dengan solusi yang tepat seperti metode K-Means++ dan Mini Batch K-Means, Anda dapat mengatasi tantangan ini dan meningkatkan efisiensi dan efektivitas analisis clustering Anda.
Sumber Daya Tambahan untuk Belajar Lebih Lanjut:
- Buku dan Paper: Referensi yang disebutkan sebelumnya seperti buku “Introduction to Algorithms” oleh Thomas H. Cormen, et al. dan paper “K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data” adalah sumber daya yang sangat baik untuk memahami lebih lanjut tentang K-Means dan aplikasinya.
- Kursus Online dan Tutorial: Ada banyak kursus online dan tutorial yang tersedia yang dapat membantu dalam memahami dan menerapkan algoritma K-Means.�
- Komunitas dan Forum Diskusi: Bergabung dengan komunitas seperti Stack Overflow atau forum diskusi terkait lainnya dapat sangat membantu dalam belajar dari pengalaman orang lain dan mendapatkan bantuan saat Anda menghadapi masalah atau pertanyaan.
Melalui belajar yang terstruktur dan akses ke sumber daya yang tepat, Anda dapat melanjutkan untuk memahami dan menerapkan algoritma K-Means dalam berbagai konteks dan masalah bisnis. Ini adalah langkah penting menuju menjadi praktisi data science yang lebih berpengalaman dan terampil.
Referensi
- Arthur, D., & Vassilvitskii, S. (2007). k-means++: The Advantages of Careful Seeding. Stanford InfoLab.
- Celebi, M. E., Kingravi, H. A., & Vela, P. A. (2013). A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Systems with Applications, 40(1), 200-210.
- Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). The MIT Press.
- Kanungo, T., Mount, D. M., Netanyahu, N. S., Piatko, C. D., Silverman, R., & Wu, A. Y. (2002). An Efficient k-Means Clustering Algorithm: Analysis and Implementation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(7), 881-892.
- Lloyd, S. P. (1982). Least squares quantization in PCM. IEEE Transactions on Information Theory, 28(2), 129-137.
- MacQueen, J. (1967). Some Methods for classification and Analysis of Multivariate Observations. Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability.
- Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53-65.
- Sculley, D. (2010). Web-scale k-means clustering. Proceedings of the 19th international conference on World wide web – WWW ’10.
![]()

Pendekatan Sistematis dalam Workflow Data Science

Manajemen Proyek dan Workflow dalam Data Science
